ทำ E2E Test ด้วย AI โดยใช้ Midscene.js ร่วมกับ Playwright


E2E testing แบบที่ไม่ต้องเขียน selector ในโพสต์นี้เราจะมาลองใช้ Midscene.js สำหรับควบคุบ UI แบบที่สั่งด้วย Natural language ร่วมกับ Playwright ซึ่งเป็น framework ยอดนิยมสำหรับการทำ automated browser test
Midscene.js คืออะไร?
Midscene.js เป็น JavaScript SDK ที่ใช้โมเดล LLM (เช่น GPT-4o หรือ Qwen) ในการตีความคำสั่งของเรา เช่น:
“พิมพ์art toyแล้วกดค้นหา ”
“ดึงชื่อสินค้าและราคาทั้งหมดออกมา“
และแปลงให้กลายเป็น interaction จริงในเบราว์เซอร์ โดยไม่ต้องเขียนโค้ด DOM/selector เลย
Integrate with Playwright
สำหรับใครอยากดู config แบบเต็มๆของตัว playwright รวมถึง code e2e เองสามารถไปดูใน Example Project ที่ตัว midscenejs ทำไว้เลยก็ได้
https://github.com/web-infra-dev/midscene-example/blob/main/playwright-demo
https://midscenejs.com/integrate-with-playwright.html
ในที่นี้เราจะมาลอง search chaka on popmart กัน
./e2e/popmart-search.ts
import { expect } from "@playwright/test";
import { test } from "./fixture";
test.beforeEach(async ({ page, aiTap }) => {
page.setViewportSize({ width: 1280, height: 768 });
await page.goto("https://www.popmart.com/th");
await page.waitForLoadState("load");
await aiTap('click the "ยอมรับ" (accept) button for privacy policy at the bottom of the page');
});
test("search chaka on popmart", async ({
ai,
aiQuery,
aiAssert,
aiWaitFor,
aiNumber,
aiBoolean,
aiString,
aiLocate,
}) => {
// 👀 type keywords, perform a search
await ai('type "chaka" in search box located in the top appbar, hit Enter');
// 👀 wait for the loading
await aiWaitFor("there is at least one item item on page");
// 👀 find the items
const items = await aiQuery(
"{itemTitle: string, price: Number}[], find item in list and price"
);
console.log("items", items);
expect(items?.length).toBeGreaterThan(0);
});step by step
- เข้าเว็ป https://www.popmart.com/th และรอจนเสร็จ
- เราจะใช้
aiTapสำหรับกดปุ่ม ยอมรับ ในส่วนของ cookie
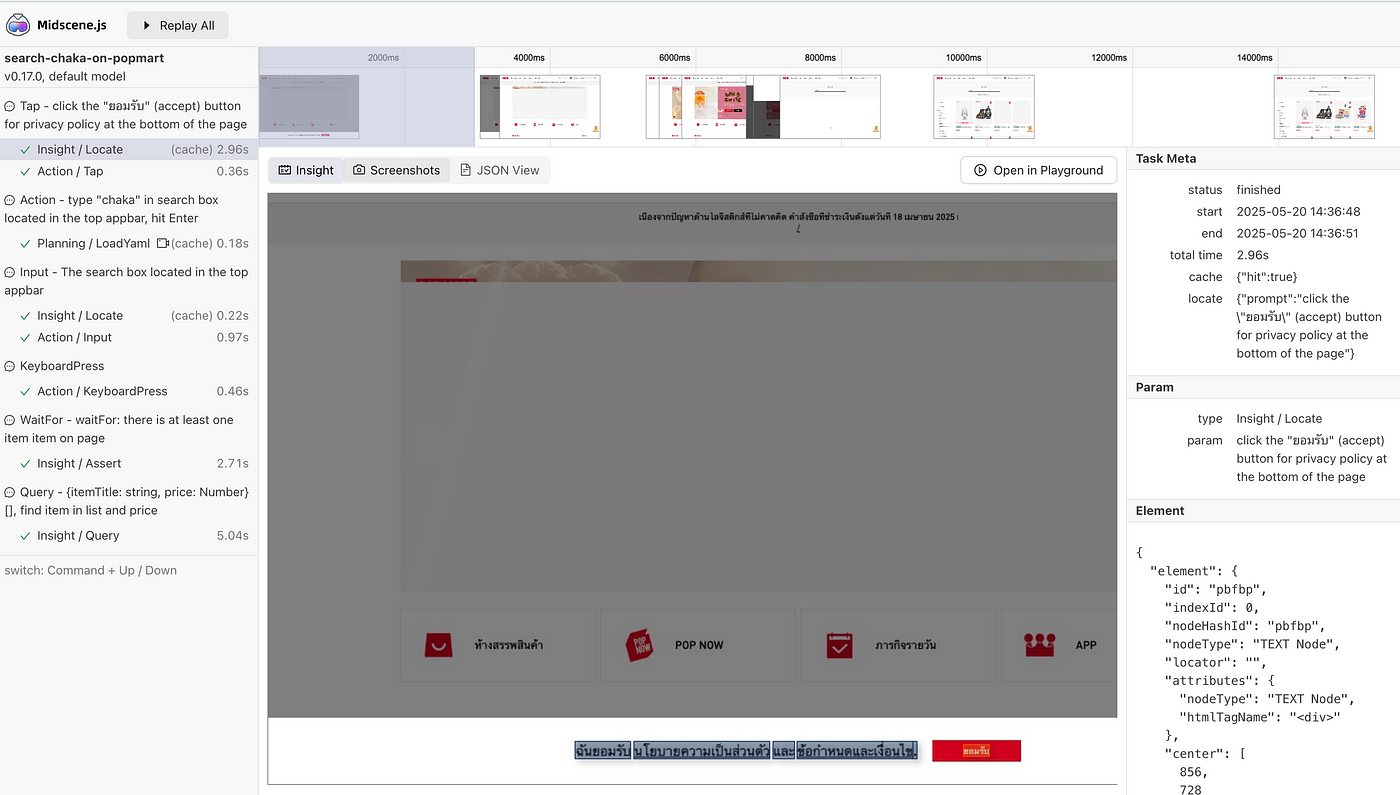
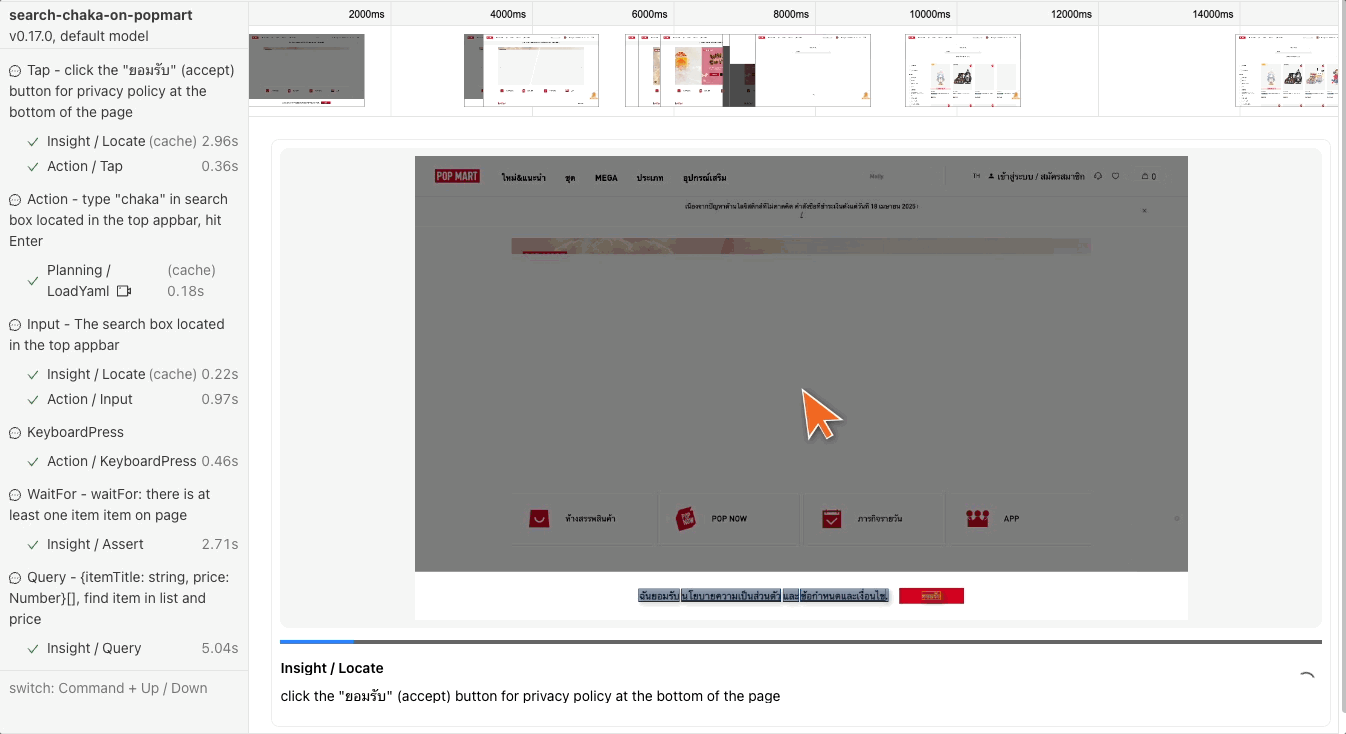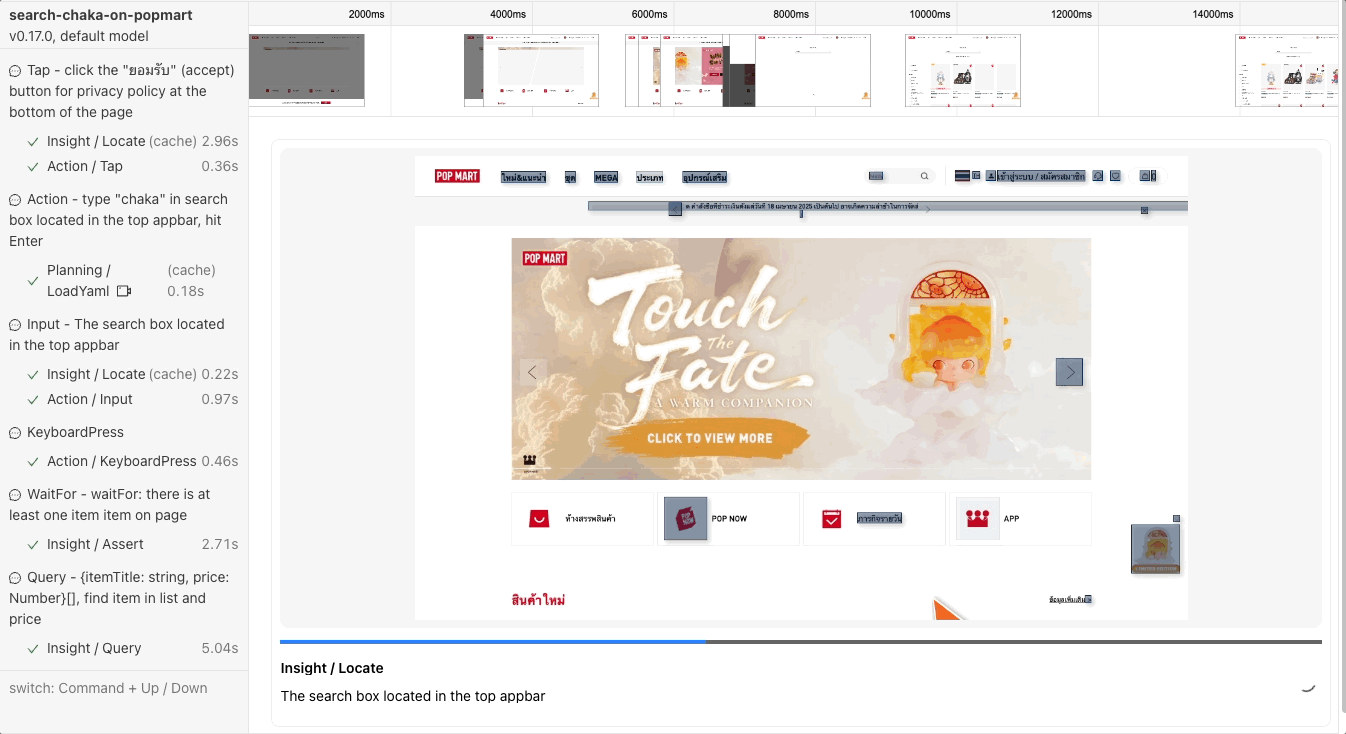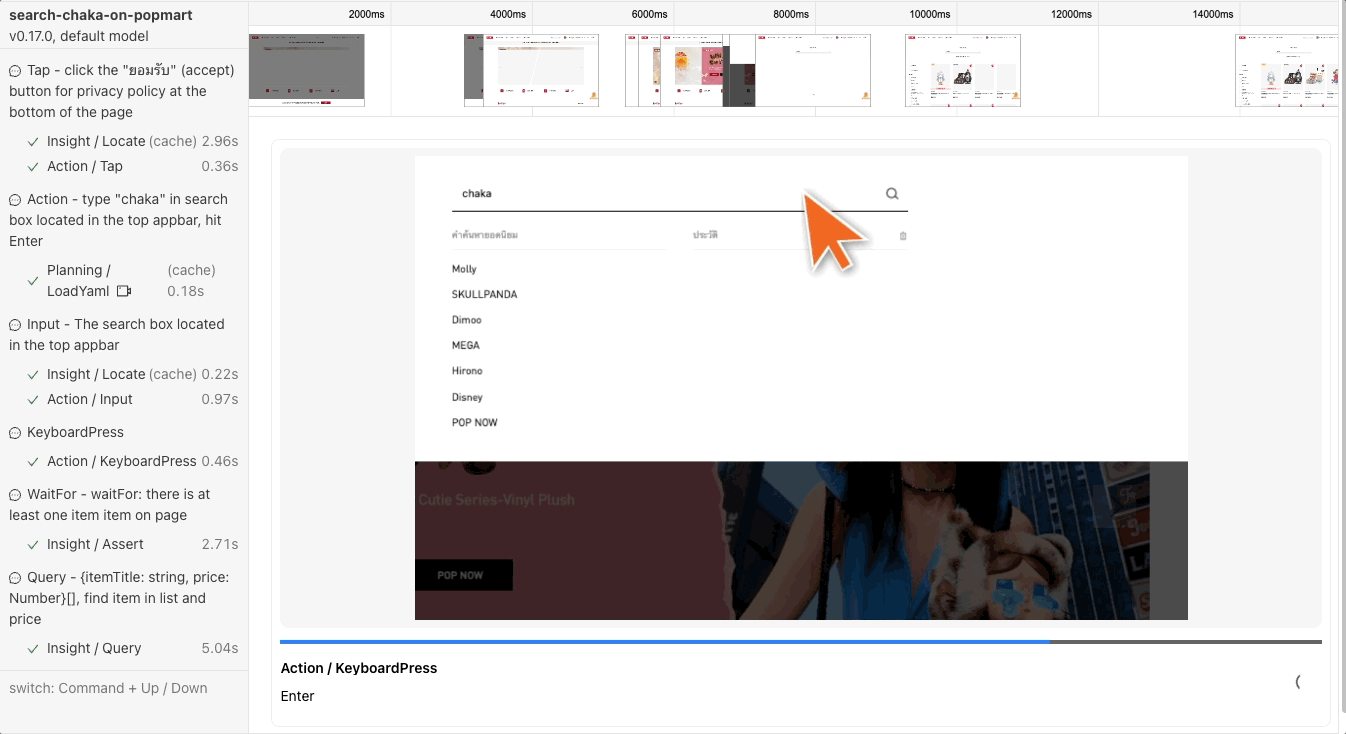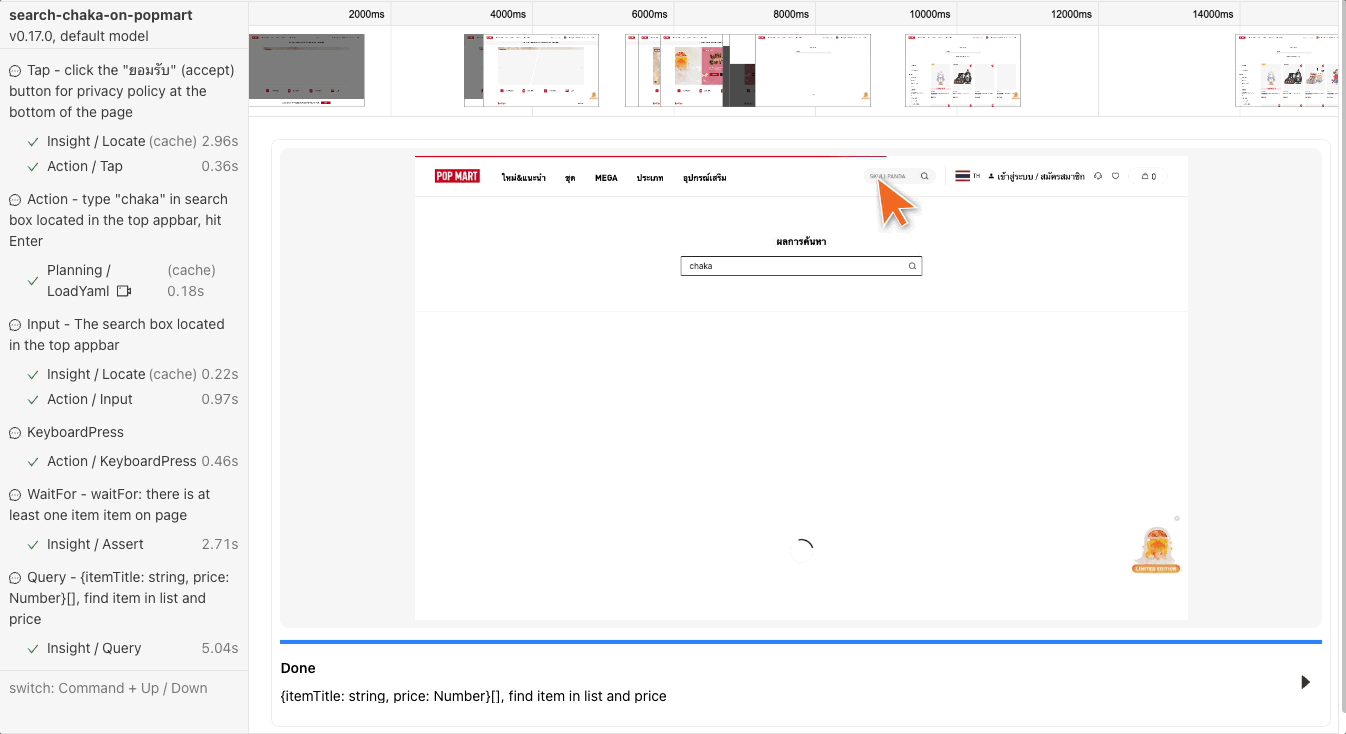
อีกหนึ่งข้อดีของการใช้ midscene คือมัน report แบบเห็นได้ในแต่ละ action ได้เลย
3. ai(‘type “chaka” in search box located in the top appbar, hit Enter’)
บอกให้ ai ไปหา search box ที่อยู่ด้านบน appbar แล้วพิมพ์ chaka แล้ว enter
ซึ่งถ้าไปลองกดหน้าเว็ปจริงๆจะเห็นได้ว่ามันไม่ได้แค่กดพิมพ์ตรงช่องนั้นได้เลยแต่
ui จะมีการโชว์เหมือน drawer ขึ้นมาอีกที ซึ่งตรงนี้มันก็สามารถที่จะจัดการได้
4.await aiWaitFor(“there is at least one item item on page”)
รอจนกว่าจะมี item โผล่ขึ้นมา
5. aiQuery เราบอกว่าให้มันช่วย query item กับ price มาให้หน่อย{itemTitle: string, price: Number}[], find item in list and price
expect ว่ามี item หรือไม่ ซึ่งจริงๆแล้วตรงนี้เราอาจจะมีการเพิ่มบอกไปด้วยก็ได้ว่า item นั้นต้องเกี่ยวกับข้องกับ keyword ที่หา (ในที่นี้ก็คือ Chaka)
แต่ต้องบอกไปก่อนว่ามันเป็นในมุมมองของ visualize แบบเป็นภาพนั้นเองแปลว่า ภาพในจอโชว์ได้แค่ไหนมันก็เห็นเท่านั้น
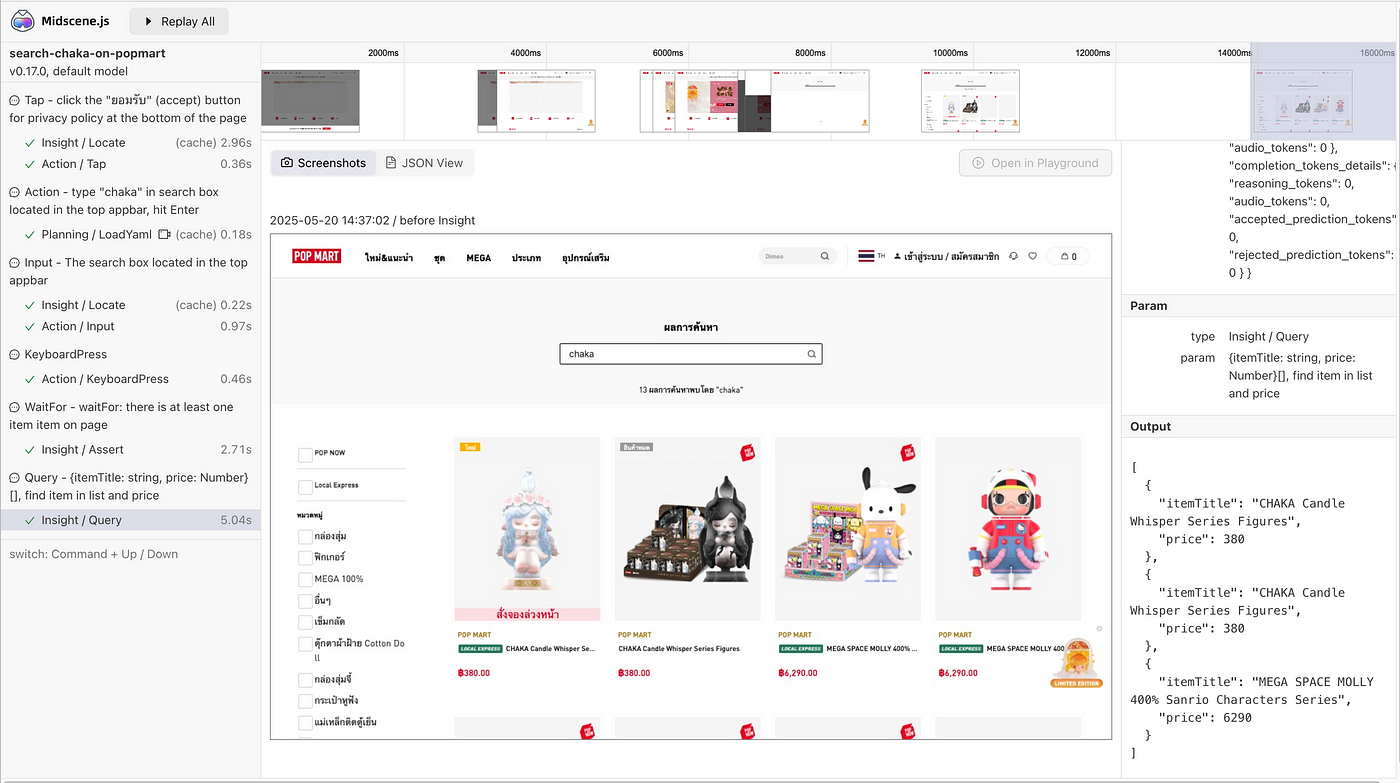
items [
{ itemTitle: 'CHAKA Candle Whisper Series Figures', price: 380 },
{ itemTitle: 'CHAKA Candle Whisper Series Figures', price: 380 },
{
itemTitle: 'MEGA SPACE MOLLY 400% Sanrio Characters Series',
price: 6290
}
]Report
หลังจาก run เสร็จเราสามารถมาดู report ในแต่ละ action ได้ ซึ่งมีการบอกด้วยว่าถ้าเป็นจังหวะที่เป็น ai มันใช้ token ไปเท่าไหร่ ใช้เวลานานแค่ไหน
Caching
เชื่อว่าหลายคนจะมีคำถามต่อมาว่า “โหแบบนี้เปลืองเงินแย่เลยถ้าต้องมายิง ai กันทุกรอบแบบนี้น่าจะช้าแถมเสียเงินเยอะแน่ๆเลย”
Midscene รองรับการ cache ขั้นตอนการวางแผนและ DOM XPath เพื่อลดการเรียกไปยังโมเดล AI ได้โดยหลังจากการ run test ครั้งแรกมันจะมีการไปสร้าง caching เป็น .yaml ไว้
midscene_run/cache/popmart.spec.ts(search-chaka-on-popmart).cache
midsceneVersion: 0.17.0
cacheId: popmart.spec.ts(search-chaka-on-popmart)
caches:
- type: locate
prompt: >-
click the "ยอมรับ" (accept) button for privacy policy at the bottom of the
page
xpaths:
- //*[@id="__next"]/div[1]/div[1]/div[4]/div[1]/div[2]/text()
- type: locate
prompt: The search box in the top appbar
xpaths:
- >-
//*[@id="__next"]/div[1]/div[1]/div[1]/div[1]/div[2]/div[2]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/img[1]
- type: plan
prompt: type "chaka" in search box located in the top appbar, hit Enter
yamlWorkflow: |
tasks:
- name: type "chaka" in search box located in the top appbar, hit Enter
flow:
- aiInput: chaka
locate: The search box located in the top appbar
- aiKeyboardPress: Enter
- type: locate
prompt: The search box located in the top appbar
xpaths:
- >-
//*[@id="__next"]/div[1]/div[1]/div[1]/div[1]/div[2]/div[1]/div[1]/text()อันนี้คือตัวอย่างหลังจาก run test popmart search ไปจะได้เห็นว่ามีการสร้าง planning กับ xpaths ไว้แล้ว
ทำให้รอบหน้าถ้าเรา run แบบ cache มันจะวิ่งด้วยคำสั่งนี้แทนไม่ไปยิง ai
ยกเว้นพวกเช่นaiBoolean,aiQuery,aiAssertจะไม่ cache เพราะเป็นการ query ไม่ใช่ action
AI Model
ด้วยความที่ midscenejs open-source project ซึ่งแยกออกจากผู้ให้บริการcloud และ modelใดๆ ทำให้เราสามารถเลือกปรับใช้แบบ public หรือ private deployment ก็ได้
ข้อดีของการใช้ AI ทำ E2E เทียบกับการเขียน test แบบปกติ
1. เข้าใจ UI แบบไม่ผูกกับ DOM selector
- ถ้า UI เปลี่ยน element type (เช่น
<button>→<a>), test script แบบ traditional จะพัง - แต่ AI จะดู context ของ UI เช่นข้อความ สี ตำแหน่งแทน
หรือบางทีเจอ expect ว่า มันเป็นวงกลมไหม มันสีแดงหรือเปล่า ?
2. สื่อสารง่ายกับทีม non-dev
- PM, Designer สามารถอ่าน test ได้
- หรือเขียน prompt เบื้องต้นได้เอง โดยไม่ต้องรู้ JavaScript
- เช่น “เปิดหน้า settings แล้วตรวจว่ามี toggle สำหรับ dark mode”
3. เหมาะกับการทดสอบเชิง business logic / high-level
4. เขียน test สำหรับ dynamic UI ได้ง่ายขึ้น
- เช่น “กดยืนยันแล้วต้องมี dialog ขึ้นคำว่า success ที่มุมบนขวา”
- Traditional test อาจต้องเขียน branch เยอะ แต่ AI เข้าใจบริบทได้ดีกว่า
แต่ทั้งนี้ทั้งนั้นสุดท้ายแล้วเราก็ไม่ควรรวม ai action ไว้ในคำสั่งเดียวอยู่ดี เราควรยังแยก action ให้ชัดเจนเพราะมันคือ Test เราคงไม่อยากได้ความไม่แน่นอนในการทำงานแต่ละครั้งแน่ๆ หากเอาไปเป็น e2e ในระบบ test
https://midscenejs.com/blog-programming-practice-using-structured-api.html
Conclusion
สุดท้ายในมุมมองของผู้เขียนเอง การใช้ AI-based testing เหมือนมี “assistant ที่เข้าใจ UI” มาช่วยเขียน test — ไม่ได้แทนทุกอย่างเราต้องเข้าใจในส่วนนี้ด้วย แต่ช่วยตอบโจทย์ในใน flow ที่เป็น user interaction จริง อาจจะมองในมุม visualize ก็ได้ เช่น เมื่อ user ทำสิ่งนี้แล้ว ควรมีสิ่งนี้เกิดขึ้นที่ในบางครั้งการจับ element อาจจะเป็นเรื่องที่ยากมาก แต่ในมุมมองที่เห็นแบบ user จริงๆเลยมันอาจจะเป็นเรื่องที่ง่ายมากๆไปเลยเช่นกัน



