[Preview] Southeast Asia LLM Function call benchmark.

![[Preview] Southeast Asia LLM Function call benchmark.](/content/images/size/w1200/2025/06/Function_Call_Benchmark.png)
What is function call
Function call capability is crucial for creating agent-based systems. Function calls allow LLMs to use 'the tools' when 'the tools' are functions (methods) or APIs.
This capability increases the reliability of LLM applications when LLM applications MUST interact with non-LLM systems.
Method
I used a part of Gorilla-eval (https://github.com/ShishirPatil/gorilla/tree/main/eval) to evaluate all models. This evaluation method measures two metrics: functionality score and hallucination score.
First, the functionality score (higher is better) means the LLM responds in the right format and with the right parameters.
Second, the hallucination score (lower is better) means the LLM responds in the right format but with incorrect parameters.
If the LLM responds in an incorrect format, it would not be counted for any score.
And I am going to run the berkeley-function-call-leaderboard (https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard) later.
Score
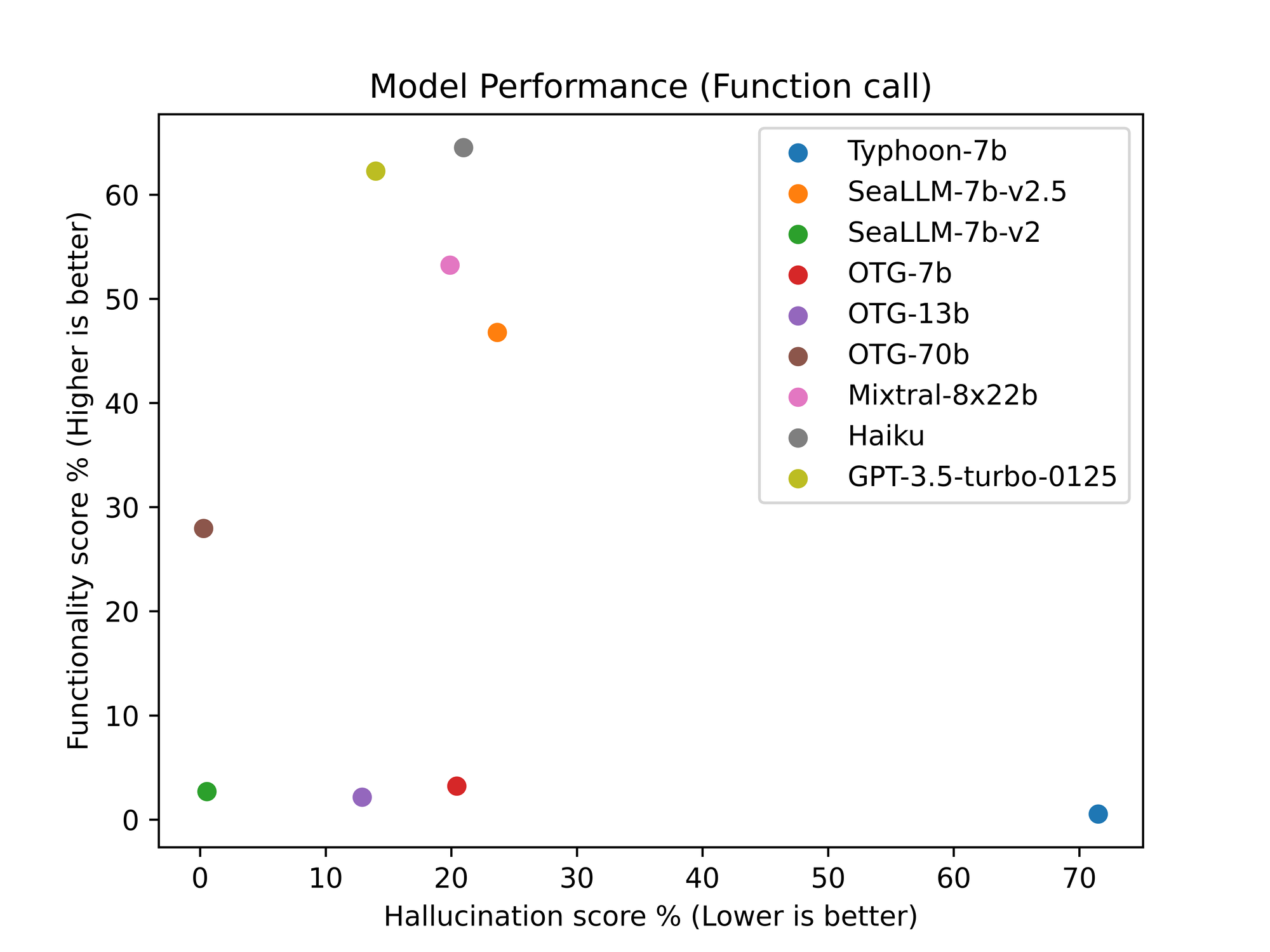
| Model | Method | Task | Functionality score | Hallucination score |
|---|---|---|---|---|
| Typhoon-7b | get_llm_responses_retriever | torchhub | 0.54% | 71.51% |
| SeaLLM-7b-v2.5 | get_llm_responses_retriever | torchhub | 46.77% | 23.66% |
| SeaLLM-7b-v2 | get_llm_responses_retriever | torchhub | 2.69% | 0.54% |
| OTG-7b | get_llm_responses_retriever | torchhub | 3.22% | 20.43% |
| OTG-13b | get_llm_responses_retriever | torchhub | 2.15% | 12.90% |
| OTG-70b | get_llm_responses_retriever | torchhub | 27.96% | 0.27% |
| Mixtral-8x22b | get_llm_responses_retriever | torchhub | 53.23% | 19.89% |
| Haiku | get_llm_responses_retriever | torchhub | 64.52% | 20.97% |
| GPT-3.5-turbo-0125 | get_llm_responses_retriever | torchhub | 62.27% | 13.98% |
What's next
I am going to run the berkeley-function-call-leaderboard and continue to add new models to the list.
And I am going to make my benchmark script public on my GitHub. Stay tuned!!
P.S. My waiting list includes Sailor-7b, Vistral-7b, and Komodo-7b. If your model is not in our list, please contact me and send me the model card.



