Launching Float16.cloud App Console v0.3

It has been almost 2 months (46 days) since the last update (v0.2.x) and the v0.3.x update. This update is a major one, adding platform capability and a new service.
V0.3
- One-click deployment
- Quantized inference speed leaderboard
One-Click Deployment
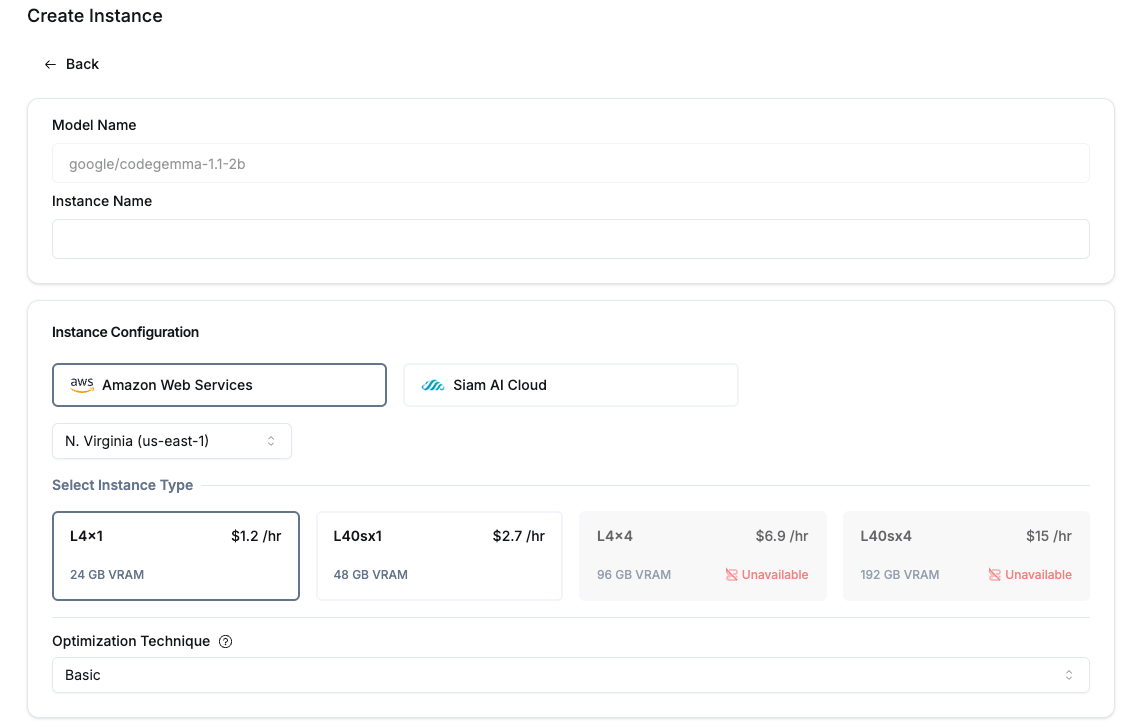
In this version, we are introducing the One-Click Deployment service. This service allows you to deploy LLMs from the Huggingface repository. We focus on ensuring that the endpoint is ready for production use, not just for a POC or experiment.
We are the world's first LLM platform to provide endpoints in Asia.
Service location
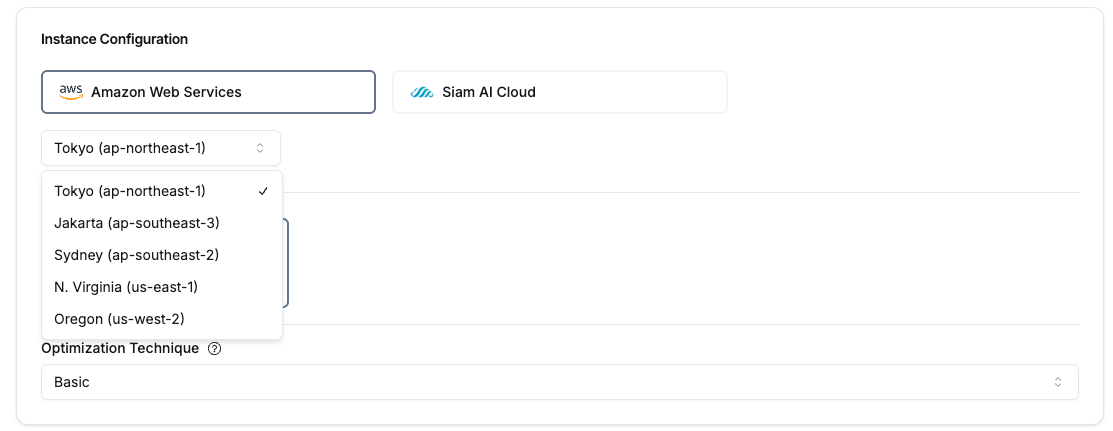
The available locations include:
- AWS - Tokyo (A10G)
- AWS - Jakarta (A10G)
- AWS - Sydney (A10G)
- AWS - N. Virginia (L4, L40s)
- AWS - Oregon (L4, L40s)
And an upcoming cloud provider (Late Oct 2024):
- Siam AI Cloud - BKK (H100, H200)
Let's explore the advanced features of our One-Click Deployment service.
OpenAI API Compatibility and Support for Code Co-Pilot via Continue.dev
The OpenAI API is essential for lowering the switching costs between different LLM providers.
OpenAI API compatibility helps developers maintain their code regardless of the framework used. The code remains the same as with the previous provider; developers just need to change the API URL and API key to switch providers.
This prevents you from having to search for the right chat template.
Technical details about Endpoint specification
Beyond OpenAI API compatibility, we also support One-Click Deployment to work with Code Co-Pilot tools like Continue.dev (a VS Code extension).
Float16 is the "World's First" provider of One-Click Deployment that is compatible with open-source Code Co-Pilot.
Why is it different ?
Several LLM providers offer Code Co-Pilot support via their "LLM as a Service," not through One-Click Deployment.
This limits the opportunity to try out various LLM code models like CodeQwen, CodeGemma, and others.
To overcome this problem, we have enabled "Context Caching" by default. More details can be found in the "Context Caching" topic.
Technical details about Endpoint specification
Long Context and Auto Scheduler

Batch size, Input length and Number token.
These 3 pillars of LLM inference determine the overall performance of model inference. Let's look at an example.
A large batch size means you can process more requests simultaneously, but the trade-off is that you need to reduce your max input per request and the average number of tokens per request.
The problem.
For self-hosted setups, you need to determine the numbers for these 3 pillars yourself. If you are unlucky in picking the numbers, you will underutilize your inference engine. To solve this problem, you have two choices:
- If you are a data scientist, you could manually calculate the 3 numbers by considering the KV cache memory required, model weight, and activation cache.
- If you are not a data scientist, you could perform a grid search to find the optimal numbers for your inference.
You have the best partner.
Float16 is the "world's first" to ensure your workload reaches maximum performance without additional work.
We automatically calculate the numbers for "ANY" model and "ANY" GPU. If the batch size exceeds the limit, we will automatically send it into a queue, and the scheduler will process it when the batch size is available.
This helps you avoid configuration complexity and endless pain. You can focus on developing the model and leave the inference to us.
Technical details about Long Context and Auto Scheduler
Quantization
Did you know quantization is not friendly to multilingual models?
Quantize is NOT the same.
Quantization is a method to compress the model in various aspects, whether it's weight, activation, or KV cache.
It is very popular for LLMs because it reduces the VRAM required to half or a quarter of a full-precision model.
Bad News.
The bad news for non-Western languages is that if you perform quantization like 4-bits weight, this will downgrade your model to 70-80% of its full-precision accuracy.
However, this phenomenon does not occur for Western languages, possibly due to the larger data proportion during pre-training.
Good News.
There is still hope. Float16 has developed and experimented with methods to prevent dramatic accuracy downgrades in multilingual models. We apply these methods by default for well-known architectures like:
- Llama (1, 2, 3, 3.1)
- Mistral
- Qwen, Qwen2
- Gemma, Gemma2

Our quantization reduces VRAM requirements to 1/2 of the full-precision model while maintaining accuracy, especially for multilingual models.
Technical details about quantization
Context caching
Caching is a very popular technique for various systems.
How about LLM inference ?
"Some" caching techniques cache relevant input "without" processing the input and send the "cache" as the response.
This is not the proper "caching" technique we want.
In few-shot prompting or RAG use cases, we only change the instruction and rationale, which may constitute just 1% or even 0.1% of the total prompt.
We don't want the same results for these cases.
How is Float16 context caching different from Google vertex context caching or Anthropic context caching ?
Our caching is very similar to Gemini context caching or Anthropic context caching but with slight differences.
Our context caching is automatic caching between contexts in the same batch size.
Instead of the system calculating 1,024 * 8 = 8,192 tokens,
the system will calculate ((1,024 - 900) * 8) + 1,024 = 2,016 tokens.
This helps the system reduce redundant computation for several cases, such as:
- Few-shot prompting
- RAG
- Code co-pilot
Float16 is the world's first to provide an endpoint with the same experience and performance as proprietary LLM providers. This technique significantly reduces latency and improves inference speed by 2 to 10 times, depending on the use case.
Because Code co-pilot triggers the endpoint multiple times with slight changes in context,
Without context caching, the endpoint latency will increase significantly, far beyond that of famous providers like GitHub Co-pilot.
With context caching, we can support Code co-pilot for "ANY" code model via One-Click Deployment.
Technical details about Context caching
Quantize inference speed leaderboard
Moreover, to develop our service, we want to create an OpenAccess benchmark dataset to provide the most comprehensive details about inference speed based on quantization techniques and KV cache.
This should help the community make easier decisions about hardware requirements during project feasibility and cost estimation.
Conclusion
We continue to develop our platform to ensure that developers have a better experience, reduce management efforts, and benefit from multiple pricing strategies.
Happy dev
Mati
Float16.cloud
Float16.cloud provides a managed GPU resource platform for developers. This includes modern GPU services like LLM as a Service, one-click deployment, serverless GPU, one-click training, and more features coming in the future.