GPU monitoring dashboard


บทความนี้ผมจะพาทุกคนมาเรียนรู้การทำ monitoring dashboard ของ GPU ด้วย grafana กันนะครับ โดยจะเริ่มกันตั้งแต่วิธีการติดตั้ง grafana จนไปถึงการตั้งค่าให้รับค่าการทำงานจาก gpu โดยใช้ dcgm-exporter ผ่าน prometheous จนสามารถสร้างเป็น dashboard ที่ดูการทำงานต่างๆของ GPU ได้ และทั้งหมดเราจะทำการ demo ด้วย docker
ในส่วนของการเตรียม instance ให้พร้อมสำหรับบทความนี้สามารถย้อนกลับไปอ่านได้ที่:
https://blog.float16.cloud/nvidia-gpu-driver-setup-essential-steps-for-llm-developers/
และถ้าทุกคนเตรียมเครื่องของตัวเองเรียบร้อยแล้ว เราไปเริ่มกันเล้ยยยย
Create docker network
เราจะให้แต่ละ container ที่เราสร้างในตัวอย่างนี้ อยู่ใน network เดียวกัน จะได้เรียกหากันได้ผ่าน container name
docker network create monitorInstall grafana
สร้าง folder สำหรับเก็บ data ของ grafana และตั้งค่า permission
mkdir grafana-data
chown -R 472:472 grafana-datacreate folder and config permission
run grafana ด้วย docker
docker run -d -p 3000:3000 --name=grafana --network monitor \
-v "./grafana-data:/var/lib/grafana" \
--user 472 \
grafana/grafana-enterpriserun grafana server
เราจะสามารถเข้าใช้งานได้ผ่าน http://localhost:3000 ด้วย user: admin และ password: admin หลังจากนั้นให้เราทำการตั้งค่า password ใหม่ให้เรียบร้อย
Install DCGM Exporter
DCGM Exporter (ย่อมาจาก Data Center GPU Manager Exporter) คือเครื่องมือจาก NVIDIA ที่ใช้สำหรับดึงข้อมูลสถานะของ GPU และส่งออกในรูปแบบที่สามารถนำไปใช้กับระบบมอนิเตอร์ เช่น Prometheus ได้อย่างง่ายดาย
การติดตั้งสามารถรันผ่าน docker ได้เลย
docker run -itd --name dcgm-exporter \
--gpus all \
--runtime=nvidia \
--cap-add SYS_ADMIN \
--network monitor \
-p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.1-ubuntu22.04ตัว service จะเป็น API ที่ return ข้อมูลของ GPU กลับมา ทดสอบได้จาก
curl http://localhost:9400/metrics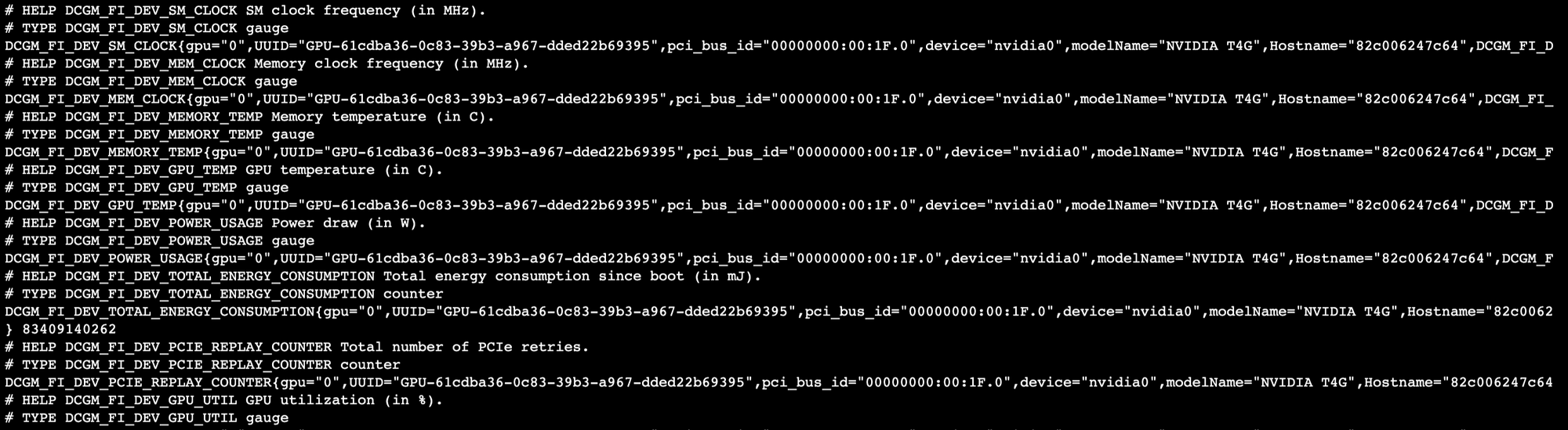
Install prometheus
สร้าง folder สำหรับเก็บ file configuration
mkdir prometheusสร้าง prometheus.yml ไว้ใน folder ที่สร้างไว้เมื่อกี้
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['dcgm-exporter:9400']สร้าง prometheus ด้วย docker
docker run -itd \
--name=prometheus \
--network monitor \
-p 9090:9090 \
-v ./prometheus:/etc/prometheus \
--user root \
prom/prometheusConfig grafana datasource
ในหน้า UI ของ grafana ให้เราเข้าไปที่ Connections > Add new connection แล้วเลือก Data source เป็น Prometheus
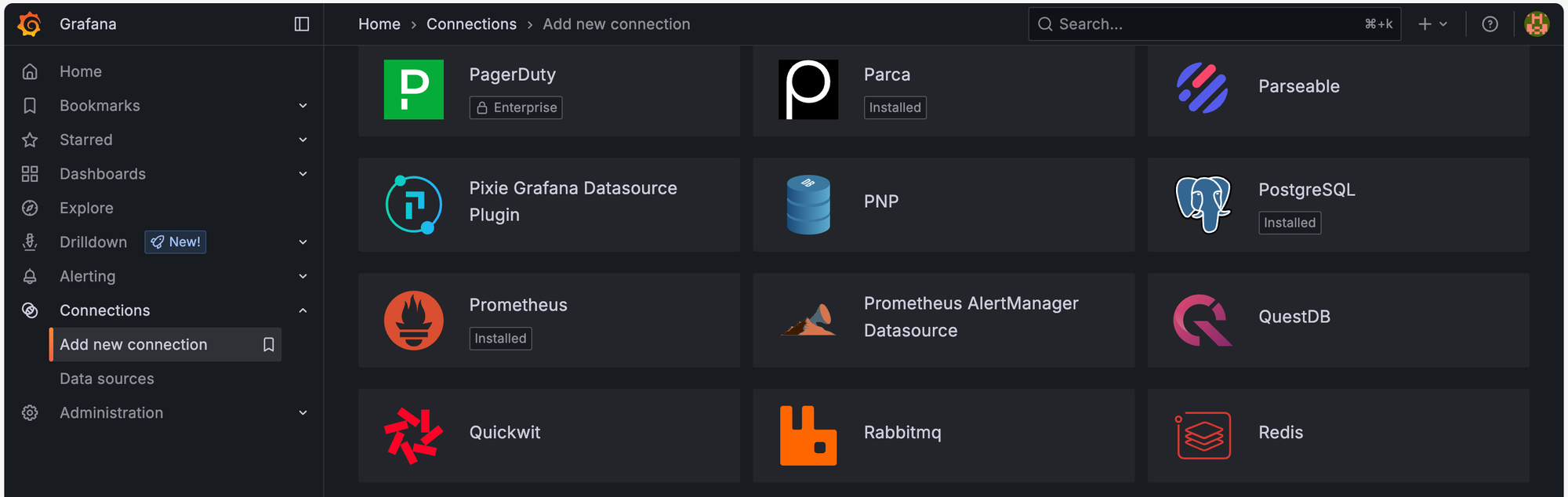
จากนั้นเลือก Add new data source
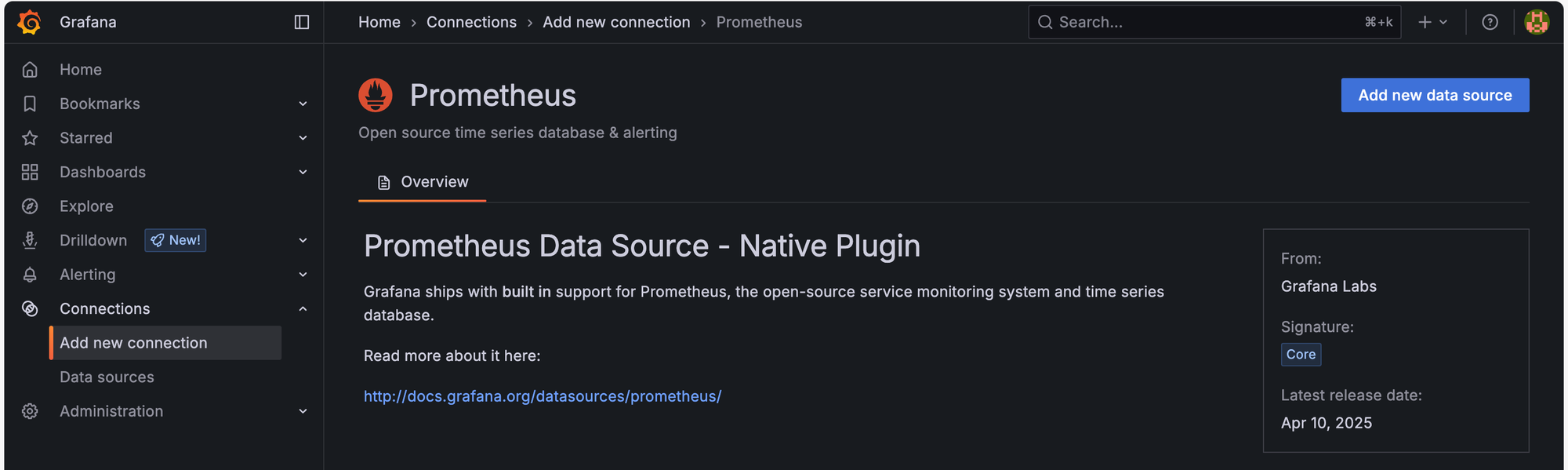
เมื่อเข้ามาหน้า setting แล้ว ตรง Connection ให้ใส่ Prometheus server URL เป็น http://prometheus:9090 จากนั้นกด save & test เพื่อสร้าง data source
Create Grafana Dashboard
ขั้นตอนนี้เราจะไม่สร้าง Dashboard เองแต่ว่าเราจะใช้ template ที่ทาง Nvidia สร้างไว้ให้จาก https://grafana.com/grafana/dashboards/12239-nvidia-dcgm-exporter-dashboard/
ใน Grafana ให้เราไปที่ Dashboard เลือก Create Dashboard จากนั้นเลือก Import dashboard
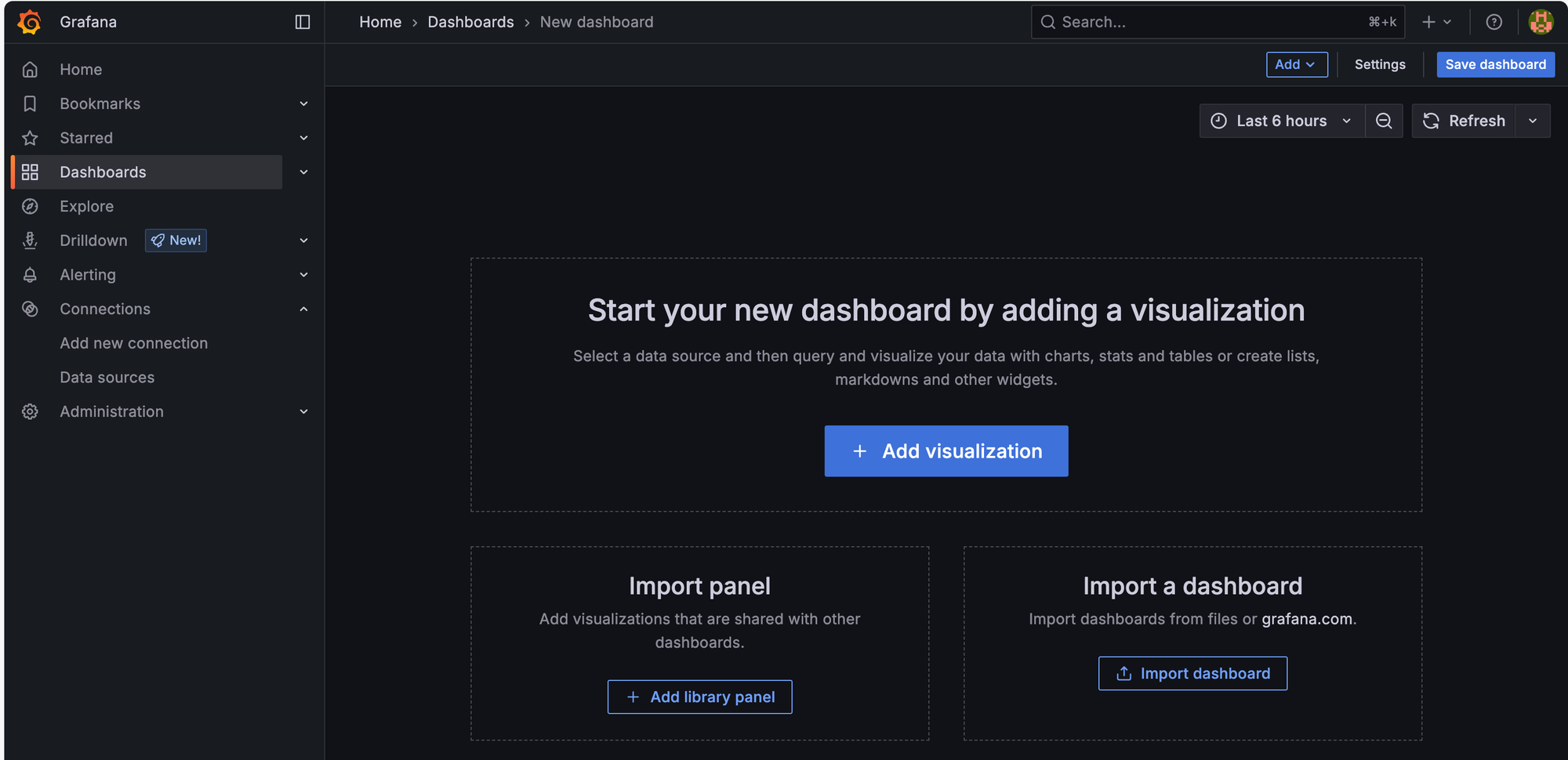
ในช่อง dashboard URL or ID ให้เราใส่ 12239 ซึ่งก็คือ id ของ nvidia dashboard จากนั้นกด load แล้วจะเข้ามาถึงหน้า Import dashboard
ใช้ช่อง Prometheus ด้านล่างให้เลือก prometheus data source ที่เราสร้างไว้ แล้วกด Import
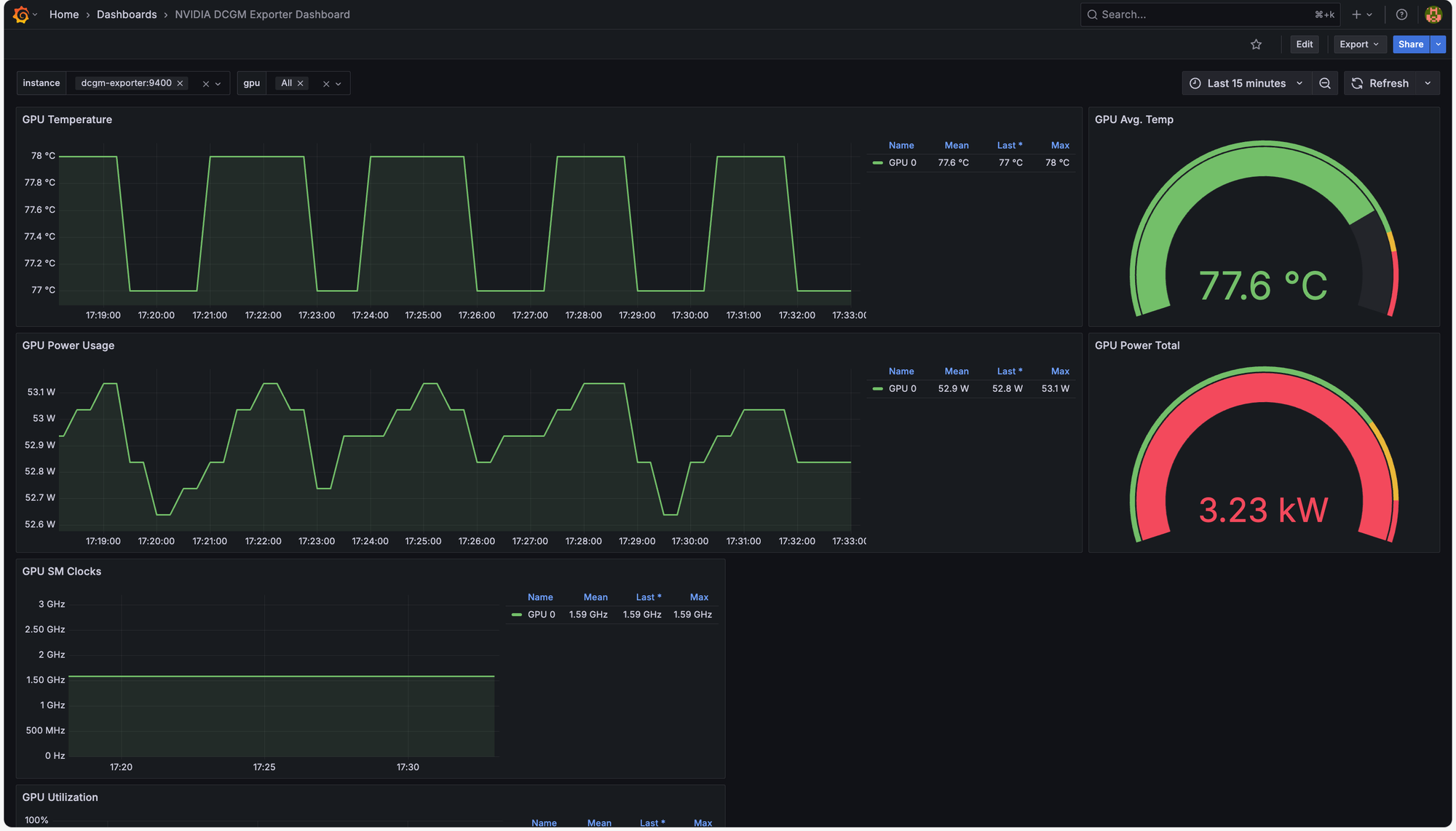
เพียงเท่านี้เราก็จะได้ GPU Dashboard ที่เอาไว้ monitor ค่าต่างๆเป็นที่เรียบร้อย
สรุปกันหน่อย
บทความนี้สำหรับท่านใดที่ใช้งานอยู่แล้วผมเชื่อว่าสามารถเอาไปปรับแต่งให้รับข้อมูลจาก DCGM-Exporter เข้าไปเพิ่มได้ไม่ยาก แต่สำหรับมือใหม่ผมเชื่อว่าสามารถทำตามตัวอย่างเหล่านี้และใช้งานได้อย่างแน่นอน หลักๆในนี้ผมแค่อยากนำเสนอตัว DCGM-Exporter ที่เป็นตัวช่วยในการดึง Metrics ต่างๆของ GPU ออกมาที่ครบถ้วนพอสมควรเลย จึงเป็น service ที่อยากเอามาแนะนำสำหรับงานนี้ครับ



