ทำ Data Extraction จาก image โดยใช้ LLM Multimodal


ในการทำ Data Extraction จากรูปภาพ เช่น สลิปใบเสร็จ, บัตรประชาชน, หรือแบบฟอร์มกระดาษ วิธีดั้งเดิมมักใช้ OCR (Optical Character Recognition) ร่วมกับการเขียน rule หรือ regex เพื่อแยกข้อมูลออกมา ซึ่งยุ่งยากหรือเมื่อรูปแบบข้อมูลเปลี่ยน
ซึ่งจริงๆแล้วเรามีอีกทางเลือกคือ LLM Multimodal
ซึ่งสามารถ "เข้าใจภาพ" และ "ตอบคำถาม" ได้โดยตรง
แนวคิด
Multimodal LLM สามารถประมวลผลทั้ง ข้อความและภาพ พร้อมกัน ทำให้เราสามารถป้อนภาพเข้าไปพร้อมกับ prompt เช่น:
ภาพนี้คือใบเสร็จร้านอาหาร กรุณาแยกข้อมูลออกมาเป็น JSON: ชื่อร้าน, วันที่, รายการอาหาร, ราคารวมCode Example
Model
สำหรับรอบนี้เราจะลองใช้ตัว gemma3-12b-vision
สามารถทำตาม Getting Started ใน README ได้เลยสำหรับใครอยากลอง deploy model เอง
Code

client-gemma3.ts
- Set prompt ให้ชัดเจนว่ารูปนี้คืออะไร ต้องการ filed อะไรบ้างพร้อมยกตัวอย่าง ถ้าไม่มีต้องทำอย่างไร และบอกว่าต้อง return ในรูปแบบ JSON เท่านั้น ซึ่งในที่นี้เราจะมีการบอกเพิ่มด้วยว่าต้อง ดูเรื่องของ
categoryด้วยว่าคืออะไร ถ้าเป็นinvoiceค่อยให้ดึง field ที่เราต้องการออกมา แต่ถ้าไม่ใช่ให้บอกว่ามันคืออะไร
This is an image of a document. Please analyze the document and return a JSON object that strictly follows the schema below:
{
"category": string, // Document category: "invoice", "receipt", or "other-[description]"
"result": object | null // Invoice data if category is "invoice", otherwise null
}
If the document category is "invoice", return the result as:
{
"category": "invoice",
"result": {
"invoice_number": string, // e.g. "INV-2024-00123"
"invoice_date": string, // Date as shown in document (any format: DD/MM/YYYY, MM-DD-YYYY, YYYY-MM-DD, etc.)
"due_date": string | null, // Date as shown in document (any format) or null if not found
"total_amount": number | null, // Final total amount (e.g. 1234.50) in INR
"items": [
{
"description": string, // Name of the product or service
"quantity": number | null,
"unit_price": number | null,
"line_total": number | null
}
]
}
}
If the document category is NOT "invoice", return the result as:
{
"category": "receipt" | "other-[description]",
"result": null
}
DOCUMENT CATEGORY GUIDELINES:
- "invoice": Only tax invoices, billing invoices, commercial invoices
- "receipt": Payment receipts, transaction receipts
- "other-[description]": For any other content, describe what you see after "other-"
Examples: "other-id_card", "other-child_photo", "other-certificate", "other-bill", "other-menu", "other-text_document"
IMPORTANT INSTRUCTIONS:
- Only extract invoice data if the document category is clearly "invoice"
- For receipts, use exactly "receipt" as the category
- For anything else, use "other-" followed by a brief English description of what you see
- For dates, extract them exactly as they appear in the document - do not convert or reformat
- For all non-invoice documents, set result to null
- Do not guess or fabricate values
- Return ONLY the JSON object directly. Do not wrap it in markdown code blocks (${"`"}json${"`"})
- Do not include any explanation, comments, or extra text before or after the JSON
- Your response should start with { and end with }
- The response must be valid JSON that can be parsed directly- โยน image ผ่าน type
image_urlใน content message คู่ไปกลับ
const { data } = await axios.post(
`${process.env.BASE_URL}/chat/completions`,
{
model: "gemma3-12b-vision",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
{
type: "image_url",
image_url: { url: `data:image/jpeg;base64,${image}` },
},
],
},
],
},
{
headers: {
Authorization: `Bearer ${process.env.API_KEY}`,
"Content-Type": "application/json",
},
}
);client-openai.ts
สำหรับกรณีใช้แบบ Model อื่นที่ OpenAI Completions และรองรับ Multimodal
Result
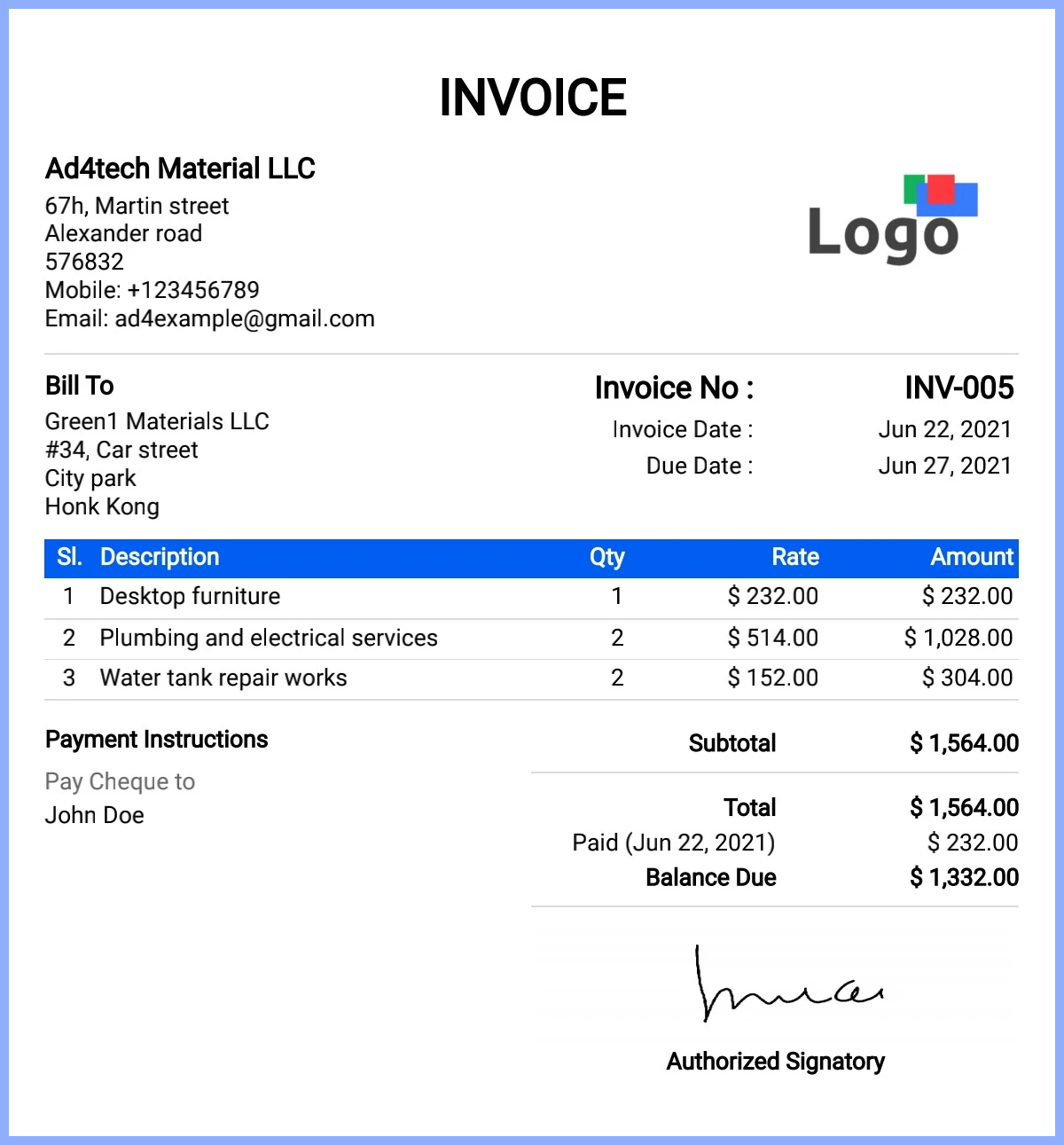
{
"category": "invoice",
"result": {
"invoice_number": "INV-005",
"invoice_date": "Jun 22, 2021",
"due_date": "Jun 27, 2021",
"total_amount": 1564,
"items": [
{
"description": "Desktop furniture",
"quantity": 1,
"unit_price": 232,
"line_total": 232
},
{
"description": "Plumbing and electrical services",
"quantity": 2,
"unit_price": 514,
"line_total": 1028
},
{
"description": "Water tank repair works",
"quantity": 2,
"unit_price": 152,
"line_total": 304
}
]
}
}
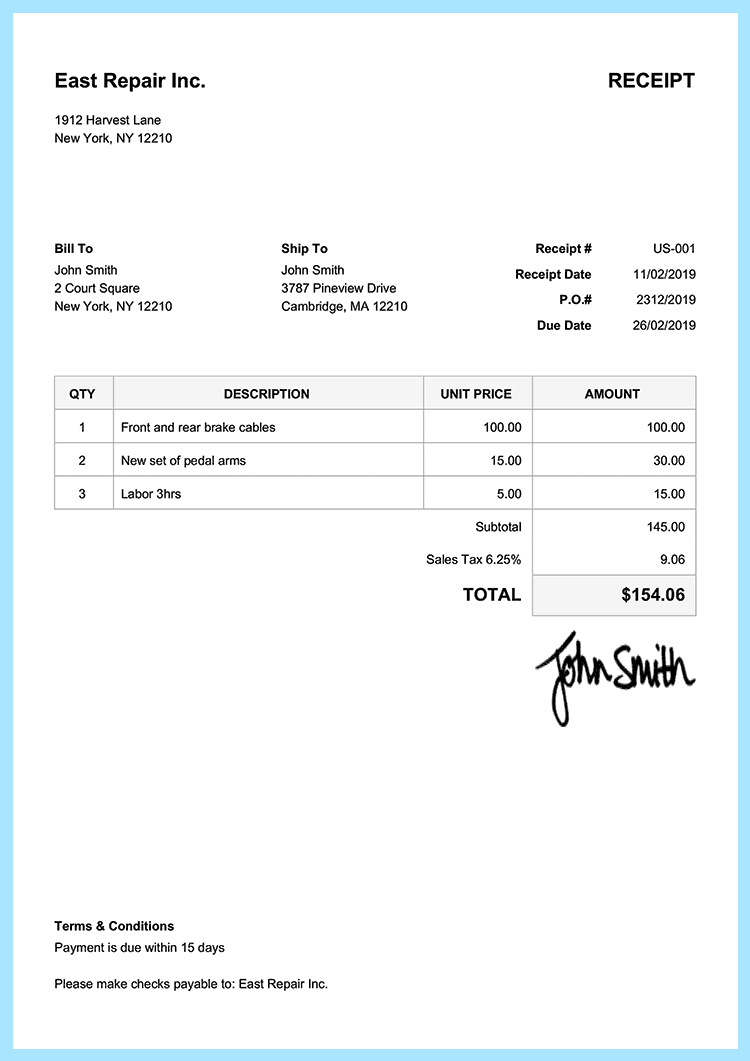
{
"category": "invoice",
"result": {
"invoice_number": "100",
"invoice_date": "1/30/23",
"due_date": "1/30/23",
"total_amount": 420,
"items": [
{
"description": "20\" x 30\" hanging frames",
"quantity": 10,
"unit_price": 15,
"line_total": 150
},
{
"description": "5\" x 7\" standing frames",
"quantity": 50,
"unit_price": 5,
"line_total": 250
}
]
}
{
"category": "receipt",
"result": null
}ข้อดี
- ใช้ได้กับหลายรูปแบบ (แม้ layout จะเปลี่ยน)
- เจาะจงข้อมูลที่ต้องการได้ผ่าน prompt
- ไม่ต้องเขียน regex หรือ template เฉพาะเอกสาร
- สามารถเพิ่ม condition เข้าไปได้เช่น ถ้าเป็น a ถึงค่อยหยิบ b
ข้อควรระวัง
- ราคาค่อนข้างสูง (คิดตาม token)
- ความแม่นยำขึ้นอยู่กับ prompt และความชัดของภาพ
- ควรมี fallback หรือ validation เผื่อโมเดลตอบผิด
ถ้าเปรียบเทียบไปทำในรูปแบบ OCR
- OCR: แปลงรูปภาพให้เป็น text
- OCR Post-processing: ปรับปรุงข้อความที่ได้จาก OCR ให้ถูกต้องมากขึ้น
- Text Extraction & Cleaning: ดึงข้อความสำคัญและทำความสะอาดข้อมูล
- Document Structure Understanding: เข้าใจโครงสร้างเอกสาร (ใบเสร็จ, ใบเบิก, รายงานอนุมัติ)
- Named Entity Recognition (NER): ระบุว่านี้ชื่อบริษัท, วันที่, จำนวนเงิน, เลขที่เอกสาร
Conclusion
การใช้ LLM Multimodal สำหรับ Data Extraction จากภาพเป็นแนวทางที่ดีมากหากโดยเฉพาะในกรณีที่เอกสารมีฟิลด์จำนวนมาก แล้วเราอาจจะอยากหยิบแค่บางฟิลด์ที่เฉพาะจง แล้ว layout อาจจะไม่มีความแน่นอน หรือ condition บางอย่างในการจะดึงข้อมูล เราสามารถควบคุมผ่าน prompt ได้ โดยไม่ต้องสร้างระบบ parsing ที่ซับซ้อน ทำให้เราไม่จำเป็นต้องไปยึดติดอีกต่อไปว่าการทำแบบนี้ต้องทำ OCR อย่างเดียว แล้วมานั้งทำ regex หรือมานั้งวิเคราะห์ต่อเพื่อดึงข้อมูลที่เราต้องการจริงๆออกมา
จากตัวอย่างที่ยกมาจะเป็น Data Extraction ออกมาแบบง่ายๆ ซึ่งจริงๆแล้วยังสามารถทำได้อีกหลากหลายท่า จะเพิ่ม condition บางอย่าง จะเอาไปทำ Classification/Validation ก็ได้
Float16
Managed GPU resource platform for developers. Experience the cheapest serverless GPU in spot mode and the fastest GPU endpoint in deploy mode.
Connect with us:
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud



